
【導(dǎo)讀】由于FPGA具有強大邏輯資源、豐富IP核等優(yōu)點,基于FPGA的嵌入式系統(tǒng)架構(gòu)是機載視頻圖形顯示系統(tǒng)理想的架構(gòu)選擇。本文以Kintex-7系列XC7K410T FPGA芯片和兩片MT41J128M16 DDR3 SDRAM芯片為硬件平臺,設(shè)計并實現(xiàn)了基于FPGA的視頻圖形顯示系統(tǒng)的DDR3多端口存儲管理。
機載視頻圖形顯示系統(tǒng)主要實現(xiàn)2D圖形的繪制,構(gòu)成各種飛行參數(shù)畫面,同時疊加實時的外景視頻。由于FPGA具有強大邏輯資源、豐富IP核等優(yōu)點,基于FPGA的嵌入式系統(tǒng)架構(gòu)是機載視頻圖形顯示系統(tǒng)理想的架構(gòu)選擇。視頻處理和圖形生成需要存儲海量數(shù)據(jù),F(xiàn)PGA內(nèi)部的存儲資源無法滿足存儲需求,因此需要配置外部存儲器。
與DDR2 SDRAM相比,DDR3 SDRAM帶寬更好高、傳輸速率更快且更省電,能夠滿足吞吐量大、功耗低的需求,因此選擇DDR3 SDRAM作為機載視頻圖形顯示系統(tǒng)的外部存儲器。
本文以Kintex-7系列XC7K410T FPGA芯片和兩片MT41J128M16 DDR3 SDRAM芯片為硬件平臺,設(shè)計并實現(xiàn)了基于FPGA的視頻圖形顯示系統(tǒng)的DDR3多端口存儲管理。
1 總體架構(gòu)設(shè)計
機載視頻圖形顯示系統(tǒng)中,為了實現(xiàn)多端口對DDR3的讀寫訪問,設(shè)計的DDR3存儲管理系統(tǒng)如圖 1所示。主要包括DDR3存儲器控制模塊、DDR3用戶接口仲裁控制模塊和幀地址控制模塊。
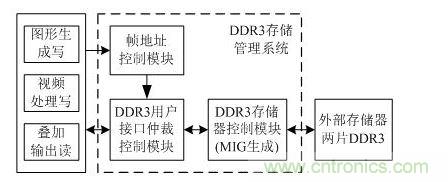
圖 1 DDR3存儲管理系統(tǒng)設(shè)計框圖
DDR3存儲器控制模塊采用MIG(Memory Interface Generator)方案,通過用戶接口建立FPGA內(nèi)部控制邏輯到DDR3的連接,用戶不需要管理DDR3初始化、寄存器配置等復(fù)雜的控制邏輯,只需要控制用戶接口的讀寫操作。
DDR3用戶接口仲裁控制模塊將每一個數(shù)據(jù)讀寫請求設(shè)置成中斷,借鑒中斷處理思想來進行仲裁控制,從而解決數(shù)據(jù)存儲的沖突。
幀地址控制模塊控制幀地址的切換。為了提高并行處理的速度,簡化數(shù)據(jù)讀寫沖突,將圖形數(shù)據(jù)和視頻數(shù)據(jù)分別存儲在不同的DDR3中。
2 DDR3存儲器控制模塊設(shè)計
MIG生成的DDR3控制器的邏輯框圖如圖 2所示,只需要通過用戶接口信號就能完成DDR3讀寫操作,大大簡化了DDR3的設(shè)計復(fù)雜度。
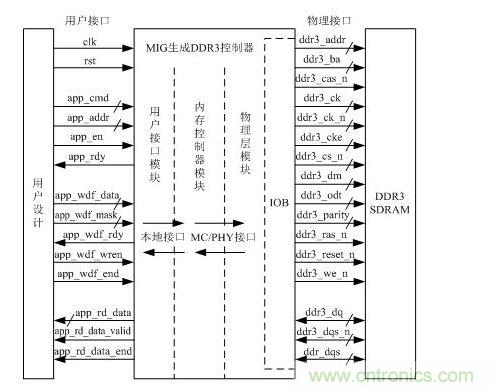
圖 2 DDR3控制器的邏輯框圖
[page]
2.1 DDR3控制模塊用戶接口寫操作設(shè)計
DDR3存儲器控制模塊用戶接口寫操作有兩套系統(tǒng),一套是地址系統(tǒng),一套是數(shù)據(jù)系統(tǒng)。用戶接口寫操作信號說明如表 1所示。
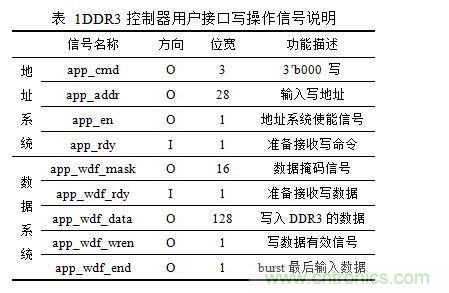
地址系統(tǒng)的內(nèi)容是app_addr和app_cmd,兩者對齊綁定,app_cmd為000時為寫命令,當app_rdy(DDR3控制)和app_en(用戶控制)同時拉高時,將app_addr和app_cmd寫到相應(yīng)FIFO中。數(shù)據(jù)系統(tǒng)的內(nèi)容是app_wdf_data,它在app_wdf_rdy(DDR3控制)和app_wdf_wren(用戶控制)同時拉高時,將寫數(shù)據(jù)存到寫FIFO。
為了簡化設(shè)計,本文設(shè)計的用戶接口寫操作時序如圖 3所示,使兩套系統(tǒng)在時序上完全對齊。
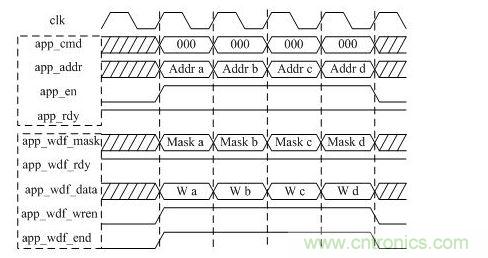
圖 3 DDR3寫操作時序圖(突發(fā)長度BL=8)
2.2 DDR3控制模塊用戶接口讀操作設(shè)計
用戶接口讀操作也分為地址系統(tǒng)和數(shù)據(jù)系統(tǒng)。用戶接口讀操作信號說明如表 2所示。
地址系統(tǒng)與寫操作相同,在時鐘上升沿且app_rdy為高電平時,用戶端口同時發(fā)出讀命令(app_cmd=001)和讀地址,并將app_en拉高,將讀命令和地址寫到FIFO中。對于數(shù)據(jù)系統(tǒng),當app_rd_data_valid有效,則讀數(shù)據(jù)有效,讀回的數(shù)據(jù)順序與地址/控制總線請求命令的順序相同。
讀操作地址系統(tǒng)和數(shù)據(jù)系統(tǒng)一般是不對齊的,因為地址系統(tǒng)發(fā)送到DDR3后,DDR3需要一定的反應(yīng)時間,讀操作時序如圖 4所示。
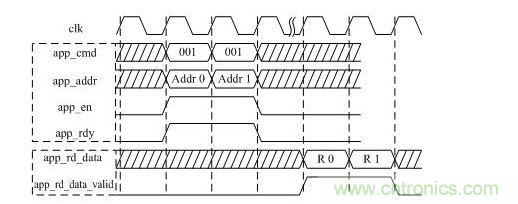
圖 4 DDR3讀操作時序圖(突發(fā)長度BL=8)
[page]
3 DDR3用戶接口仲裁控制模塊設(shè)計
每片DDR3只有一組控制、地址和數(shù)據(jù)總線,因此同一時刻只能有一個設(shè)備在訪問。常見的總線切換方式有兩種:一種是輪詢機制,軟件實現(xiàn)簡單,但實時性不高;一種是仲裁機制,設(shè)備發(fā)送中斷請求,從而進行總線切換。由于視頻圖形顯示系統(tǒng)對實時性要求高,因此選擇仲裁機制。
DDR3用戶接口仲裁控制框圖如圖 5所示。為了提高并行速度,將圖形和視頻分別進行中斷處理。將設(shè)備中斷請求解析成多個子請求,進行優(yōu)先級判斷,每個子請求對應(yīng)一個中斷處理邏輯。
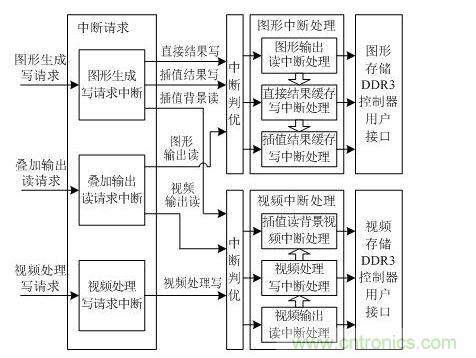
圖 5 DDR3用戶接口仲裁控制設(shè)計框圖
3.1 視頻處理寫請求中斷處理器設(shè)計
由于視頻處理寫請求不涉及到圖形中斷處理,所以對應(yīng)一個子請求:視頻處理寫子請求。
視頻處理模塊將采集到的視頻經(jīng)過縮放、旋轉(zhuǎn)等操作后存儲在緩存區(qū)中,當緩存區(qū)滿時發(fā)送視頻處理模塊寫請求。視頻處理寫中斷處理主要是從視頻處理模塊的緩存區(qū)中將地址和數(shù)據(jù)取出,寫入到視頻存儲DDR3中。
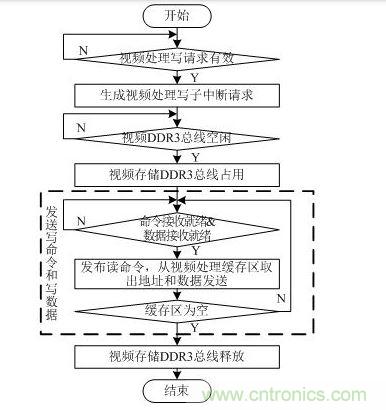
圖 6 視頻處理寫請求中斷處理流程圖
視頻處理寫請求中斷處理流程圖如圖 6所示。當視頻處理模塊寫請求信號有效時,生成子中斷請求信號,若總線空閑則響應(yīng)該中斷。當命令接收就緒(app_rdy=1)且數(shù)據(jù)接收就緒(app_wdf_rdy=1)時,從視頻處理緩存區(qū)中讀取地址和數(shù)據(jù),同時發(fā)送寫命令、寫地址和寫數(shù)據(jù)。若緩存區(qū)為空,說明全部寫完,視頻處理寫中斷結(jié)束。
[page]
3.2 疊加輸出讀請求中斷處理器設(shè)計
疊加輸出模塊需要從DDR3中將待輸出的圖形數(shù)據(jù)和視頻數(shù)據(jù)存儲到行緩存中,因此分為兩個子請求:視頻輸出讀請求和圖形輸出讀請求。由于兩者分別在圖形中斷處理和視頻中斷處理中完成,因此可以同時進行。
視頻輸出讀中斷處理主要從視頻存儲DDR3中讀取1行視頻數(shù)據(jù)寫入到疊加輸出模塊的視頻緩存區(qū)中,流程圖如圖 7所示。本系統(tǒng)中突發(fā)長度為BL=8,即每個用戶時鐘周期對應(yīng)接收同一行地址中相鄰的8個存儲單元的連續(xù)數(shù)據(jù)。輸出視頻分辨率為cols×rows,則地址系統(tǒng)需要發(fā)送cols/8個突發(fā)讀命令。數(shù)據(jù)系統(tǒng)接收讀數(shù)據(jù)時,若讀數(shù)據(jù)有效(app_rd_data_valid=1),則將讀到的數(shù)據(jù)存儲到疊加輸出模塊的視頻緩存區(qū)中,同時讀數(shù)據(jù)個數(shù)加1。當讀數(shù)據(jù)個數(shù)為cols/8時,所有讀命令對應(yīng)的讀數(shù)據(jù)全部接收,視頻輸出讀中斷處理結(jié)束。
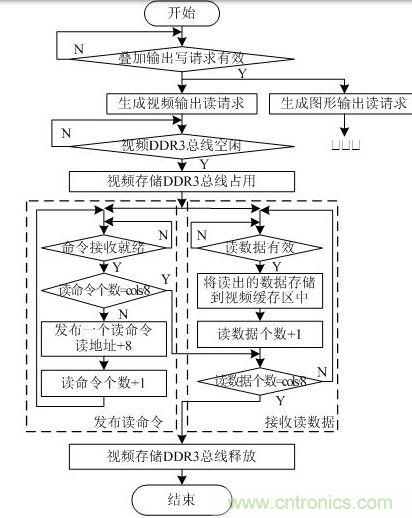
圖 7視頻輸出讀中斷處理流程圖
圖形輸出讀中斷處理包含兩個步驟:從圖形存儲DDR3中讀取1行圖形數(shù)據(jù)寫到疊加輸出模塊的圖形緩存區(qū)中;將剛剛搬移數(shù)據(jù)到圖形緩存區(qū)的DDR3存儲空間清零。前者與視頻輸出讀中斷的處理過程類似。
圖形數(shù)據(jù)寫入DDR3時只寫入有圖形的位置,而不是全屏掃描,如果不進行清屏操作會導(dǎo)致下一幀圖形畫面上殘留上一幀的圖形數(shù)據(jù)。清屏操作指圖形輸出后將DDR3中對應(yīng)地址的存儲空間全部寫入數(shù)值0,從而將當前圖形數(shù)據(jù)清除。
3.3 圖形生成寫請求中斷處理器設(shè)計
圖形生成是接收CPU的圖形命令并進行光柵化,將結(jié)果先存儲在直接結(jié)果緩存區(qū)和插值結(jié)果緩存區(qū)中,從而存入到DDR3中。當一幀圖形全部繪制完成后發(fā)送圖形生成模塊寫請求。圖形生成寫請求分為三個子請求:直接結(jié)果寫中斷請求、插值背景讀中斷請求、插值結(jié)果寫中斷請求。
直接結(jié)果緩存區(qū)存放直接輸出的與背景顏色無關(guān)的像素值數(shù)據(jù);插值結(jié)果緩存區(qū)存放需要讀回對應(yīng)位置的背景視頻進行插值修正的像素點的數(shù)據(jù)。插值結(jié)果寫到DDR3時,首先從視頻存儲DDR3中讀出需要修正的像素點對應(yīng)位置的視頻像素值作為背景,然后用流水線處理實現(xiàn)插值修正,最后將修正結(jié)果寫到圖形存儲DDR3中。
為了提高讀寫速度,圖形中斷處理器中先進行直接結(jié)果寫中斷處理;同時視頻中斷處理器中進行插值背景視頻讀中斷處理。同時完成后再進行插值結(jié)果寫中斷處理。流程與圖 6和圖 7相似。
4 幀地址控制模塊設(shè)計
幀地址控制模塊主要是將DDR3空間進行劃分,同時控制幀地址的切換。為了簡化設(shè)計,將存儲器劃分為若干塊,每塊存儲一幀數(shù)據(jù),在用戶仲裁控制模塊讀寫緩存區(qū)時只生成幀內(nèi)地址,幀地址的切換由幀讀寫控制模塊實現(xiàn),幀內(nèi)地址結(jié)合幀地址組合成對應(yīng)DDR3的內(nèi)部地址值。DDR3的幀地址劃分如圖 8所示。
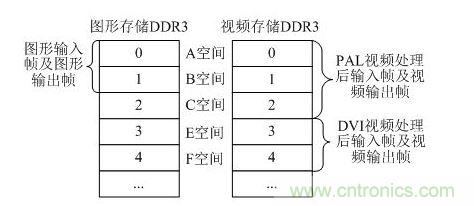
圖 8 DDR3幀地址劃分
圖形的讀寫和DVI視頻的讀寫不涉及幀速率的轉(zhuǎn)換,因此圖形存儲DDR3中的第0~1幀和視頻存儲DDR3中的第3~4幀地址控制方式相同,都是其中一幀用于將生成數(shù)據(jù)寫入到DDR3中,另一幀用于讀出數(shù)據(jù)疊加輸出,兩幀交替使用,通過乒乓操作來實現(xiàn)圖形數(shù)據(jù)的存儲與讀取。
視頻存儲DDR3中,第0~2幀(又稱A空間、B空間和C空間)用于PAL視頻處理后輸入幀及視頻輸出幀。由于PAL視頻幀速率為25Hz,而最終輸出DVI的幀速率為60Hz,因此需要實現(xiàn)幀速率轉(zhuǎn)換。常見的幀速率轉(zhuǎn)換算法[8]包括:幀復(fù)制法、幀平均法、運動補償法等,由于機載系統(tǒng)對實時性要求比較高,因此選用幀復(fù)制法。
設(shè)置三個幀存儲空間,其中一幀用于讀出,一幀用于寫入,還有一幀空閑,分別稱作輸入幀、輸出幀和空閑幀。用三者的切換來實現(xiàn)幀速率的轉(zhuǎn)換,確保輸出幀相對于當前輸入幀的延遲最小,即當前輸出幀輸出的是最新寫滿的幀。當寫入的幀存儲空間已經(jīng)寫滿,而讀存儲空間還沒讀完,將下一幀的圖像數(shù)據(jù)寫到當前空閑的幀存儲空間。圖 9為PAL輸入幀和輸出幀讀寫控制流程圖。以A空間為輸出幀,B空間為輸入幀,C空間為空閑幀為例。若A空間讀完,B空間寫滿,則將B空間變成輸出幀并輸出,將C空間變成輸入幀并繼續(xù)輸入;若A空間還沒有讀完,B空間已經(jīng)寫滿,則將下一幀數(shù)據(jù)寫入到C空間,并繼續(xù)從A空間輸出。
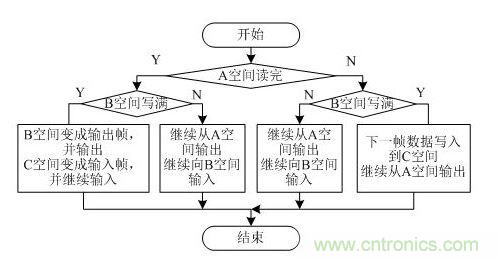
圖 9 PAL輸入幀和輸出幀讀寫控制流程圖
[page]
5 驗證結(jié)果與分析
圖形生成寫中斷處理仿真圖如圖 10所示。由于圖形生成數(shù)據(jù)不是從左往右連續(xù)進行的,因此每次突發(fā)寫操作發(fā)送的128位數(shù)據(jù)(BL=8),有效的數(shù)據(jù)只有低16位,高112位直接用掩碼屏蔽(app_wdf_mask=16’hfffc)。當一幀圖形全部繪制完成后發(fā)送圖形生成模塊寫請求(graphics_done=1)。此時圖形中斷處理器執(zhí)行直接結(jié)果寫中斷(graphics_wr_interrupt=1),視頻中斷處理器執(zhí)行插值背景讀中斷(graphics_wr_interrupt_rd_bk=1)。當兩者同時完成(rd_bk_video_finish=1)時,圖形中斷處理器執(zhí)行插值結(jié)果寫請求中斷。其中,c0_app_XXX表示圖形存儲DDR3的用戶接口,寫圖形數(shù)據(jù)時,用戶接口地址系統(tǒng)和數(shù)據(jù)系統(tǒng)是對齊的;c1_app_XXX表示視頻存儲DDR3的用戶接口,讀視頻背景時,數(shù)據(jù)系統(tǒng)比地址系統(tǒng)稍有延遲。
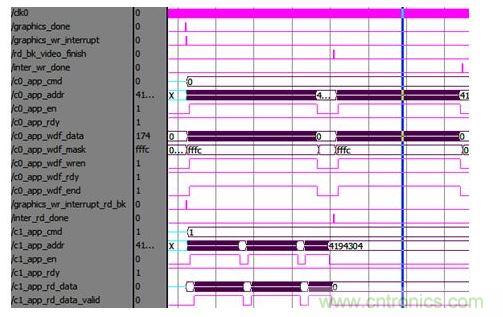
圖 10圖形生成寫中斷處理波形圖
用本文設(shè)計的DDR3存儲管理系統(tǒng)對文獻[9]中圖6.1進行中斷處理。視頻分辨率為1600×1200;繪制字符等直接結(jié)果點共812個像素(矩形填充忽略不算);繪制斜線等插值結(jié)果點共有4762個像素。用本文算法測試各中斷處理時間如表 3所示。
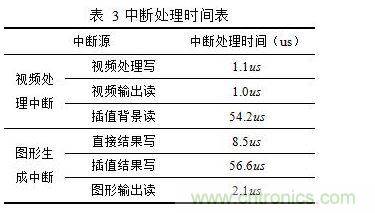
視頻中斷處理器中,視頻處理寫中斷將一行視頻處理數(shù)據(jù)順序?qū)懭氲紻DR3中耗時1.1us,則將一幀視頻處理數(shù)據(jù)寫入DDR3中耗時1.32ms;視頻輸出讀中斷從DDR3讀出1行視頻數(shù)據(jù)耗時1us,則將一幀視頻讀出需要1.2ms;插值背景讀耗時54.2us。視頻處理中斷共耗時2.5742ms。圖形處理中斷中,圖形輸出讀中斷讀出1行圖形數(shù)據(jù),并將其內(nèi)存空間清零,共需要2.1us,即將一幀圖形讀出需要2.52ms,則圖形處理中斷共耗時2.5851ms。
與文獻[9]結(jié)果相比,本文設(shè)計的系統(tǒng)對圖形生成讀寫中斷速度有了明顯提高。因為文獻[9]中斷類型較多,且圖形生成中斷的優(yōu)先級最低,在實現(xiàn)的過程中會多次被打斷,導(dǎo)致圖形生成執(zhí)行時間較長;而本文算法中,插值背景讀操作與直接結(jié)果寫操作同時在視頻中斷處理和圖形中斷處理中進行,利用并行操作減少時間,并大大降低了復(fù)雜度。
結(jié)論
本文設(shè)計并實現(xiàn)了基于FPGA的DDR3多端口存儲管理,主要包括DDR3存儲器控制模塊、DDR3用戶接口仲裁控制模塊和幀地址控制模塊。DDR3存儲器控制模塊采用Xilinx公司的MIG方案,簡化DDR3的邏輯控制;DDR3用戶接口仲裁控制模塊將圖形和視頻分別進行中斷處理,提高了并行速度,同時簡化仲裁控制;幀地址控制模塊將DDR3空間進行劃分,同時控制幀地址的切換。
經(jīng)過分析,本文將圖形和視頻中斷分開處理,簡化多端口讀寫DDR3的復(fù)雜度,提高并行處理速度。

