
【導(dǎo)讀】過(guò)去二十年來(lái),基于 DRAM 的計(jì)算機(jī)內(nèi)存的存取帶寬已經(jīng)提升了 20 倍,容量增長(zhǎng)了 128 倍。但延遲表現(xiàn)僅有 1.3 倍的提升,卡內(nèi)基梅隆大學(xué)的研究者 Kevin Chang 如是說(shuō),他提出了一種用于解決該問(wèn)題的新型數(shù)據(jù)通路…
如果人類創(chuàng)造了一個(gè)真正有自我意識(shí)的人工智能,那么等待數(shù)據(jù)到達(dá)可能會(huì)讓它倍感沮喪。
過(guò)去二十年來(lái),基于 DRAM 的計(jì)算機(jī)內(nèi)存的存取帶寬已經(jīng)提升了 20 倍,容量增長(zhǎng)了 128 倍。但延遲表現(xiàn)僅有 1.3 倍的提升,卡內(nèi)基梅隆大學(xué)的研究者 Kevin Chang 如是說(shuō),他提出了一種用于解決該問(wèn)題的新型數(shù)據(jù)通路。
現(xiàn)代計(jì)算機(jī)需要大量高速度、高容量的內(nèi)存才能保證持續(xù)運(yùn)轉(zhuǎn),尤其是工作重心是內(nèi)存數(shù)據(jù)庫(kù)、數(shù)據(jù)密集型分析以及越來(lái)越多的機(jī)器學(xué)習(xí)和深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練功能的數(shù)據(jù)中心服務(wù)器。盡管研究人員已經(jīng)在尋找更好、更快的替代技術(shù)上努力了很多年,但在性能優(yōu)先的任務(wù)上,DRAM 仍舊是人們普遍采用的選擇。
這有助于解釋今年的 DRAM 銷量激增,盡管據(jù) IC Insights 報(bào)告稱供應(yīng)有限讓其平均售價(jià)增長(zhǎng)了 74%。售價(jià)激增讓 DRAM 市場(chǎng)收入達(dá)到了創(chuàng)紀(jì)錄的 720 億美元,幫助將 IC 市場(chǎng)的總收入推升了 22%。據(jù)這份 IC Insights 報(bào)告說(shuō),如果沒(méi)有來(lái)自 DRAM 價(jià)格的額外增長(zhǎng)(過(guò)去 12 個(gè)月增長(zhǎng)了 111%),那么 2017 年整個(gè) IC 市場(chǎng)的增長(zhǎng)將只能達(dá)到 9%,相比而言 2016 年僅有 4%。
對(duì)于 DRAM 這樣一個(gè)很多人都想替代的成熟技術(shù)而言(因?yàn)樗乃俣冗_(dá)不到處理器一樣快),這個(gè)數(shù)字確認(rèn)驚人。當(dāng)前或未來(lái)有望替代 DRAM 的技術(shù)有很多,但專家們似乎認(rèn)為這些技術(shù)還無(wú)法替代 DRAM 的性價(jià)比優(yōu)勢(shì)。就算用上 DRAM 技術(shù)上規(guī)劃的改進(jìn)方案以及 HBM2 和 Hybrid Memory Cube 等新型 DRAM 架構(gòu),DRAM 和 CPU 之間的速度差距依然還是存在。
Rambus 的系統(tǒng)與解決方案副總裁和杰出發(fā)明家 Steven Woo 在 CTO 辦公室中說(shuō),來(lái)自 JEDEC 的下一代 DRAM 規(guī)格 DDR5 的密度和帶寬都是 DDR4 的 2 倍,可能能夠帶來(lái)一些提速。
對(duì)于需要密集計(jì)算而且對(duì)時(shí)間敏感的金融技術(shù)應(yīng)用以及其它高端分析、HPC 和超級(jí)計(jì)算應(yīng)用而言,這將會(huì)非常重要——尤其是當(dāng)與專用加速器結(jié)合起來(lái)時(shí)。
Woo 說(shuō):“對(duì)更高內(nèi)存帶寬和更大內(nèi)存容量的需求是顯然存在的,但 DDR5 本身并不足以滿足這些需求,我們也不清楚其它哪些技術(shù)可能會(huì)取得成功。我們已經(jīng)看到很多處理過(guò)程(比如加密貨幣挖礦和神經(jīng)網(wǎng)絡(luò)訓(xùn)練)正從傳統(tǒng)的 x86 處理器向 GPU 和專用芯片遷移,或者對(duì)架構(gòu)進(jìn)行一些修改,讓數(shù)據(jù)中心中的處理更靠近數(shù)據(jù)的存儲(chǔ)位置,就像邊緣計(jì)算或霧計(jì)算。”
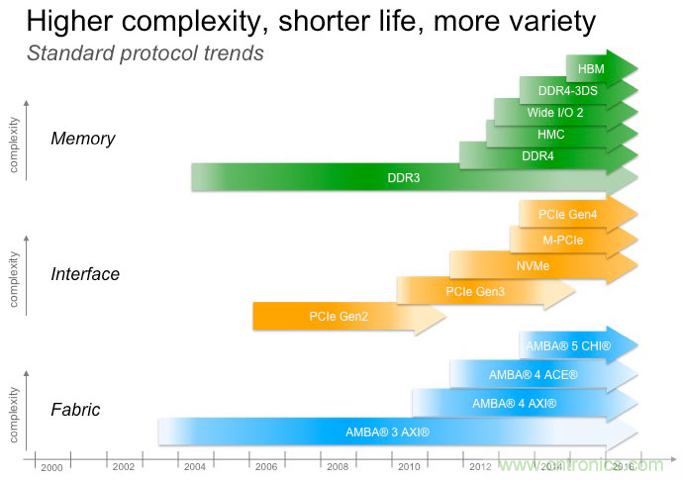
圖 1:新標(biāo)準(zhǔn)的引入(source: Cadence)
據(jù) Babblabs 公司 CEO 兼斯坦福大學(xué) System X 的戰(zhàn)略顧問(wèn) Chris Rowen 說(shuō),對(duì)于在神經(jīng)網(wǎng)絡(luò)上訓(xùn)練機(jī)器學(xué)習(xí)應(yīng)用而言,GPU 顯然最受歡迎的,但芯片制造商和系統(tǒng)制造商也在實(shí)驗(yàn)一些稍微成熟的技術(shù),比如 GDDR5,這是一種為游戲機(jī)、顯卡和 HPC 開發(fā)的同步圖形 RAM,英偉達(dá)也正是這么使用它的。
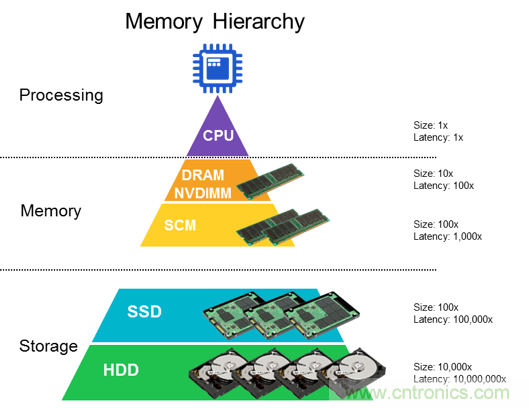
圖 2:內(nèi)存在芯片層次結(jié)構(gòu)中的位置(source:Rambus)
由 SK 海力士和三星制造的 HBM2 將一些高速 DRAM 芯片放在了增加了一些邏輯處理的層級(jí)以及提供了到處理器的高速數(shù)據(jù)鏈路的 interposer 之上,從而讓內(nèi)存與處理器之間的距離比 GDDR5 的設(shè)計(jì)更近。HBM2 是高速度至關(guān)重要的 2.5D 封裝中的一項(xiàng)關(guān)鍵元素。HBM2 是一項(xiàng)與 Hybrid Memory Cube 相競(jìng)爭(zhēng)的 JEDEC 標(biāo)準(zhǔn)。Hybrid Memory Cube 是由 IBM 和美光開發(fā)的,使用了過(guò)硅通孔(TSV)來(lái)將不同的內(nèi)存層連接到基礎(chǔ)邏輯層。
應(yīng)用硅光子學(xué)的光學(xué)連接(optical connection)也能實(shí)現(xiàn)加速。到目前維持,大多數(shù)硅光子學(xué)應(yīng)用都在數(shù)據(jù)中心中的服務(wù)器機(jī)架和存儲(chǔ)之間以及高速網(wǎng)絡(luò)連接設(shè)備內(nèi)部。業(yè)內(nèi)專家預(yù)計(jì)這種技術(shù)將會(huì)在未來(lái)幾年里向離處理器更近的位置遷移,尤其是當(dāng)其封裝技術(shù)得到完全驗(yàn)證并且設(shè)計(jì)流程將這項(xiàng)技術(shù)包含進(jìn)來(lái)之后。光學(xué)方法的優(yōu)勢(shì)是發(fā)熱很慢而且速度非常快,但光波還是要在轉(zhuǎn)換成電信號(hào)之后才能存儲(chǔ)和處理數(shù)據(jù)。
另外還有 Gen-Z、CCIX、OpenCAPI 等新型互連標(biāo)準(zhǔn),也有 ReRAM、英特爾的相變 3D Xpoint、 3D NAND 和磁相變 MRAM 等新型內(nèi)存類型。
NVDIMM 速度更慢但容量更大,增加電池或超級(jí)電容可以實(shí)現(xiàn)非易失性,從而讓它們可以使用更低的功耗緩存比普通 DRAM 更多的數(shù)據(jù),并且還能保證它們?cè)跀嚯姇r(shí)不會(huì)丟失交易數(shù)據(jù)。據(jù)八月份來(lái)自 Transparency Market Research 的一份報(bào)告稱,支持 NVDIMM 的芯片制造商包括美光和 Rambus,預(yù)計(jì)其銷售額將會(huì)從 2017 年的 7260 萬(wàn)美元增長(zhǎng)到 2025 年的 1.84 億美元。
選擇這么多,可能會(huì)讓人困惑,但針對(duì)機(jī)器學(xué)習(xí)或大規(guī)模內(nèi)存數(shù)據(jù)庫(kù)或視頻流來(lái)調(diào)整內(nèi)存性能會(huì)讓選擇更輕松一些,因?yàn)槠渲忻糠N任務(wù)都有不同的瓶頸。Rowen 說(shuō):“實(shí)現(xiàn)帶寬增長(zhǎng)有一些主流的選擇——DDR3、DDR4、DDR5,但你也可以嘗試其它選擇,從而讓內(nèi)存帶寬滿足你想做的事情。”
Rowen 說(shuō),對(duì)于有意愿編寫直接控制 NAND 內(nèi)存的代碼的人來(lái)說(shuō),整個(gè)問(wèn)題可能還會(huì)更簡(jiǎn)單;而如果是鼓搗協(xié)議和接口層,讓 NAND 看起來(lái)就像是硬盤并且掩蓋在上面寫入數(shù)據(jù)的難度,那就可能會(huì)更加困難。“有了低成本、容量和可用性,我認(rèn)為在讓閃存存儲(chǔ)包含越來(lái)越多存儲(chǔ)層次上存在很多機(jī)會(huì)。” 冷卻 DRAM
Rambus 的內(nèi)存與接口部門的首席科學(xué)家 Craig Hampel 說(shuō),每一種內(nèi)存架構(gòu)都有自己的優(yōu)勢(shì),但它們都至少有一個(gè)其它每一種集成電路都有的缺點(diǎn):發(fā)熱。如果你能可靠地排出熱量,你就可以將內(nèi)存、處理器、圖形協(xié)處理器和內(nèi)存遠(yuǎn)遠(yuǎn)更加緊密地堆積到一起,然后可以在節(jié)省出的空間中放入更多服務(wù)器,并且還能通過(guò)減少內(nèi)存與系統(tǒng)其它組件之間的延遲來(lái)提升性能。
液體冷卻是讓絕緣礦物油流經(jīng)組件的冷卻方法。據(jù) IEEE Spectrum 2014 年的一篇文章稱,液體冷卻讓香港的比特幣挖礦公司 Asicminer 的 HPC 集群的冷卻成本降低了 97%,并且還減少了 90% 的空間需求。
自 2015 年以來(lái),Rambus 就一直在與微軟合作開發(fā)用于量子計(jì)算的內(nèi)存,這是微軟開發(fā)拓?fù)淞孔佑?jì)算機(jī)工作的一部分。因?yàn)榱孔犹幚砥髦荒茉诔蜏丨h(huán)境下運(yùn)行(低于 -292℉/-180℃/93.15K),所以 Rambus 正為該項(xiàng)目測(cè)試的 DRAM 也需要在這樣的環(huán)境下工作。Rambus 在 4 月份時(shí)擴(kuò)展了該項(xiàng)目,那時(shí)候 Hampel 說(shuō)該公司已經(jīng)確信寒冷能帶來(lái)重大的性能增益。
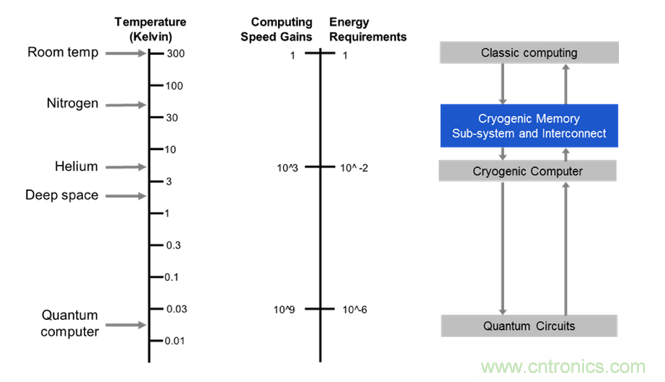
圖 3:低溫計(jì)算和存儲(chǔ)(source: Rambus)
比如,當(dāng) CMOS 足夠冷時(shí),CMOS 芯片的數(shù)據(jù)泄露(data leak)就會(huì)完全停止。幾乎就會(huì)變成非易失的。它的性能會(huì)增長(zhǎng),能讓內(nèi)存的速度趕上處理器的速度,從而消除 IC 行業(yè)內(nèi)一大最頑固的瓶頸。在 4K 到 7K 這樣極端低溫的環(huán)境下,線材將變成超導(dǎo)體,讓芯片僅需非常少的能量就能實(shí)現(xiàn)長(zhǎng)距離通信。
低溫系統(tǒng)還有額外的優(yōu)勢(shì)。比起空調(diào)制冷,低溫系統(tǒng)能從堆疊的內(nèi)存芯片中抽取出更多熱量,從而可實(shí)現(xiàn)更大的堆疊(或其它組裝方式)密度,實(shí)現(xiàn)更高效的協(xié)作。Hampel 說(shuō):“抽取熱量讓你能將服務(wù)器機(jī)架的大小減小多達(dá) 70%,這意味著數(shù)據(jù)中心每立方英尺的密度增大了。這讓它們更容易維護(hù),也可以更容易地將它們放在之前無(wú)法到達(dá)的地方。”
更重要的是,如果在處理器層面上實(shí)現(xiàn)的效率提升與數(shù)據(jù)中心其它地方的提升基本一致,那么低溫系統(tǒng)可以讓現(xiàn)有的數(shù)據(jù)中心更有成本效益和實(shí)現(xiàn)更高效的計(jì)算,從而可以減少對(duì)更多數(shù)據(jù)中心的需求。
而且不需要非常冷就可以收獲其中大多數(shù)效益;將內(nèi)存冷卻到 77K(-321℉/-196℃)就能得到大多數(shù)效益了。
Hampel 說(shuō):“液氮很便宜——每加侖幾十美分,而且在達(dá)到大約 4 K 的超級(jí)冷之前,成本上漲其實(shí)也并不快。降到50K 左右其實(shí)并不貴。” 接近處理器
據(jù) Marvell 存儲(chǔ)部門總監(jiān) Jeroen Dorgelo 說(shuō),超低溫冷卻可以延長(zhǎng)數(shù)據(jù)中心中 DRAM 的壽命,但隨著行業(yè)從 hyperscale 規(guī)模向 zettascale 規(guī)模演進(jìn),已有的任何芯片或標(biāo)準(zhǔn)都無(wú)法應(yīng)付這樣的數(shù)據(jù)流。他說(shuō),DRAM 雖快但功率需求大。NAND 不夠快,不適合擴(kuò)展,而大多數(shù)前沿的內(nèi)存(3D XPoint、MRAM、ReRAM)也還無(wú)法充分地?cái)U(kuò)展。
但是大多數(shù)數(shù)據(jù)中心還沒(méi)有處理好變得比現(xiàn)在遠(yuǎn)遠(yuǎn)更加分布式的需求。據(jù) Marvell 的連接、存儲(chǔ)和基礎(chǔ)設(shè)施業(yè)務(wù)部網(wǎng)絡(luò)連接 CTO Yaniv Kopelman 說(shuō),分布式有助于減少遠(yuǎn)距離發(fā)送給處理器的數(shù)據(jù)的量,同時(shí)可將大多數(shù)繁重的計(jì)算工作留在數(shù)據(jù)中心。
IDC 的數(shù)據(jù)中心硬件分析師 Shane Rau 說(shuō),社交網(wǎng)絡(luò)、物聯(lián)網(wǎng)和幾乎其它每個(gè)地方的數(shù)據(jù)所帶來(lái)的壓力正迫使數(shù)據(jù)中心蔓延擴(kuò)展——在全國(guó)各地建立兩三個(gè)大規(guī)模數(shù)據(jù)中心,而不是在單一一個(gè)地方建一個(gè)超大規(guī)模數(shù)據(jù)中心。
Rau 說(shuō):“規(guī)模確實(shí)不一樣,但問(wèn)題的關(guān)鍵仍然是延遲。比如說(shuō),如果我旁邊就有一個(gè)數(shù)據(jù)中心,我就不需要將我的數(shù)據(jù)移動(dòng)太遠(yuǎn)距離,而且我可以在我的筆記本電腦上完成一些處理,更多的處理則在本地?cái)?shù)據(jù)中心中進(jìn)行,所以在數(shù)據(jù)到達(dá)它要到達(dá)的位置時(shí)已經(jīng)經(jīng)過(guò)一些處理了。很多人在談將處理工作放到存儲(chǔ)的位置是為了平衡不同設(shè)備基礎(chǔ)上的瓶頸?,F(xiàn)在,規(guī)模問(wèn)題更多是關(guān)于讓數(shù)據(jù)中心在邊緣完成一些工作,即數(shù)據(jù)的產(chǎn)生位置和數(shù)據(jù)的最終去處之間。”
推薦閱讀:

