
【導(dǎo)讀】人工智能方興未艾,無數(shù)初創(chuàng)公司和老牌公司都在積極開發(fā)以人工智能應(yīng)用為賣點的智能硬件。目前,強大的云端人工智能服務(wù)(如谷歌的Alpha Go)已經(jīng)初現(xiàn)端倪,同時,人們也希望能把人工智能也帶到移動終端,尤其是能夠結(jié)合未來的物聯(lián)網(wǎng)應(yīng)用。
傳統(tǒng)實現(xiàn)移動終端人工智能的方法是通過網(wǎng)絡(luò)把終端數(shù)據(jù)全部傳送到云端,之后在云端計算后再把結(jié)果發(fā)回移動端,例如蘋果的Siri服務(wù)。然而,這樣的方式會遇到幾個問題。第一,使用網(wǎng)絡(luò)傳輸數(shù)據(jù)會產(chǎn)生延遲,很可能數(shù)據(jù)計算的結(jié)果會需要等待數(shù)秒甚至數(shù)十秒才能傳送回終端(使用過Prisma app處理過照片的朋友們應(yīng)該深有體會)。這樣一來,那些需要立刻得到計算結(jié)果的應(yīng)用就不能用這種方式。例如無人機上使用的深度學(xué)習(xí)躲避障礙物算法,如果它全部在云端執(zhí)行恐怕計算結(jié)果還沒送回來無人機已經(jīng)掉下來了。第二,一旦使用網(wǎng)絡(luò)傳送數(shù)據(jù),那么數(shù)據(jù)就有被劫持的風(fēng)險。因此,那些要求低計算延遲以及對于數(shù)據(jù)安全性非常敏感的應(yīng)用就需要把人工智能算法全部在終端實現(xiàn),或者至少在終端完成一些預(yù)處理運算然后再把少量運算結(jié)果(而不是大量的原始數(shù)據(jù))傳送到云端完成最終計算,這就需要移動終端硬件能夠快速完成這些運算。另一方面,移動端硬件完成這些運算需要的能量又不能太多,否則電池一下就沒電了(想在手機上配功耗200W+的Nvidia Pascal顯卡肯定不行!)。
目前,許多公司正在積極開發(fā)能實現(xiàn)移動端人工智能的硬件。對于移動端人工智能硬件的實現(xiàn)方法,有兩大流派,即FPGA派和ASIC派。FPGA流派的代表公司如Xilinx主推的Zynq平臺,而ASIC流派的代表公司有Movidius。兩大流派各有長短,下面讓我來細(xì)細(xì)分說。
FPGA vs. ASIC
首先講講FPGA和ASIC的區(qū)別。FPGA全稱“可編輯門陣列”(Field Programmable Gate Array),其基本原理是在FPGA芯片內(nèi)集成大量的數(shù)字電路基本門電路以及存儲器,而用戶可以通過燒入FPGA配置文件來來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,即用戶今天可以把FPGA配置成一個微控制器MCU,明天可以編輯配置文件把同一個FPGA配置成一個音頻編解碼器。ASIC則是專用集成電路(Application-Specific Integrated Circuit),一旦設(shè)計制造完成后電路就固定了,無法再改變。

用于深度學(xué)習(xí)加速器的FPGA(Xilinx Kintex 7 Ultrascle,左)和ASIC(Movidius Myriad 2,右)
比較FPGA和ASIC就像比較樂高積木和模型。舉例來說,如果你發(fā)現(xiàn)最近星球大戰(zhàn)里面Yoda大師很火,想要做一個Yoda大師的玩具賣,你要怎么辦呢?有兩種辦法,一種是用樂高積木搭,還有一種是找工廠開模定制。用樂高積木搭的話,只要設(shè)計完玩具外形后去買一套樂高積木即可。而找工廠開模的話在設(shè)計完玩具外形外你還需要做很多事情,比如玩具的材質(zhì)是否會散發(fā)氣味,玩具在高溫下是否會融化等等,所以用樂高積木來做玩具需要的前期工作比起找工廠開模制作來說要少得多,從設(shè)計完成到能夠上市所需要的時間用樂高也要快很多。FPGA和ASIC也是一樣,使用FPGA只要寫完Verilog代碼就可以用FPGA廠商提供的工具實現(xiàn)硬件加速器了,而要設(shè)計ASIC則還需要做很多驗證和物理設(shè)計(ESD,Package等等),需要更多的時間。如果要針對特殊場合(如軍事和工業(yè)等對于可靠性要求很高的應(yīng)用),ASIC則需要更多時間進(jìn)行特別設(shè)計以滿足需求,但是用FPGA的話可以直接買軍工級的高穩(wěn)定性FPGA完全不影響開發(fā)時間。但是,雖然設(shè)計時間比較短,但是樂高積木做出來的玩具比起工廠定制的玩具要粗糙(性能差)許多(下圖),畢竟工廠開模是量身定制。另外,如果出貨量大的話,工廠大規(guī)模生產(chǎn)玩具的成本會比用樂高積木做便宜許多。FPGA和ASIC也是如此,在同一時間點上用最好的工藝實現(xiàn)的ASIC的加速器的速度會比用同樣工藝FPGA做的加速器速度快5-10倍,而且一旦量產(chǎn)后ASIC的成本會遠(yuǎn)遠(yuǎn)低于FPGA方案(便宜10到100倍)。

FPGA vs ASIC :積木vs 手辦
當(dāng)然,F(xiàn)PGA還有另一大特點,就是可以隨時重新配置,從而在不同的場合實現(xiàn)不同的功能。但是,當(dāng)把FPGA實現(xiàn)的加速器當(dāng)作一個商品賣給用戶時,要讓用戶自己去重新配置卻要花一番功夫?;氐接脴犯叻e木做玩具的例子,玩具廠商可以宣稱這個Yoda大師由積木搭起來,所以玩家可以把這些積木重新組合成其他角色(比如天行者路克)。但是一般玩家根本不會拆裝積木,怎么辦?解決方案要么是把目標(biāo)市場定為精通積木的專業(yè)核心玩家,要么是在玩具后面加一個開關(guān),一般玩家只要按一下就可以讓積木自動重新組裝。很顯然,第二個方案需要很高的技術(shù)門檻。對于FPGA加速器來說,如果要把可重配置作為賣點,要么是賣給有能力自己開發(fā)FPGA的企業(yè)用戶(如百度,微軟等公司確實有在開發(fā)基于FPGA的深度學(xué)習(xí)加速器并且在不同的應(yīng)用場合將FPGA配置為不同的加速器),要么是開發(fā)一套方便易用能將用戶的深度學(xué)習(xí)網(wǎng)絡(luò)轉(zhuǎn)化為FPGA配置文件的編譯器(深鑒等公司正在嘗試)。從目前來看,即使用高端的服務(wù)器來做FPGA編譯都會需要數(shù)分鐘的時間,如果編譯在計算能力較弱的移動終端做需要的時間就更長了。對于移動終端用戶來說,如何說服他們嘗試重新配置FPGA并接受長達(dá)數(shù)十分鐘的時間來編譯網(wǎng)絡(luò)并配置FPGA仍然是一個問題。
小結(jié):
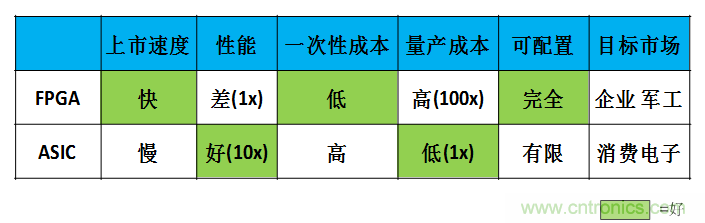
我把FPGA和ASIC的比較總結(jié)在下面表格里。FPGA上市速度快,但性能較低。ASIC上市速度慢,需要大量時間開發(fā),而且一次性成本(光刻掩模制作成本)遠(yuǎn)高于FPGA,但是性能遠(yuǎn)高于FPGA且量產(chǎn)后平均成本遠(yuǎn)低于FPGA。FPGA可以完全重配置,但是ASIC也有一定的可配置能力,只要在設(shè)計的時候就把電路做成某些參數(shù)可調(diào)的即可。目標(biāo)市場方面,F(xiàn)PGA成本太高,所以適合對價格不是很敏感的地方,比如企業(yè)應(yīng)用,軍事和工業(yè)電子等等(在這些領(lǐng)域可重配置可能真的需要)。而ASIC由于低成本則適合消費電子類應(yīng)用,而且在消費電子中可配置是否是一個偽需求還有待商榷。我們看到的市場現(xiàn)狀也是如此:使用FPGA做深度學(xué)習(xí)加速的多是企業(yè)用戶,百度、微軟、IBM等公司都有專門做FPGA的團(tuán)隊為服務(wù)器加速,而做FPGA方案的初創(chuàng)公司Teradeep的目標(biāo)市場也是服務(wù)器。而ASIC則主要瞄準(zhǔn)消費電子,如Movidius。由于移動終端屬于消費電子領(lǐng)域,所以未來使用的方案應(yīng)當(dāng)是以ASIC為主。
SoC+IP模式
說到這里,不少讀者可能有疑問:現(xiàn)在深度學(xué)習(xí)的網(wǎng)絡(luò)結(jié)構(gòu)日新月異,但是ASIC上市速度那么慢而且一旦制作完成(流片)就無法更改,如何能跟上深度學(xué)習(xí)的發(fā)展速度呢?針對這個問題,我想首先需要厘清一個概念,即用于深度學(xué)習(xí)加速的ASIC到底要做什么?有人認(rèn)為神經(jīng)網(wǎng)絡(luò)ASIC就是真的實現(xiàn)一個神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)在芯片上,因此網(wǎng)絡(luò)結(jié)構(gòu)一改(例如從12層變成15層,或者權(quán)重參數(shù)變一下)該ASIC就不能用了。其實這樣的理解是不對的:ASIC加速器做的是幫助CPU快速完成深度學(xué)習(xí)中的運算(例如卷積),當(dāng)CPU在執(zhí)行人工智能算法時只要遇到這種運算就交給加速器去做。因此只要神經(jīng)網(wǎng)絡(luò)的主要運算不變,則ASIC加速器完全可以使用。網(wǎng)絡(luò)結(jié)構(gòu)會影響ASIC加速器的性能,一種ASIC加速器可能是針對GoogleNet優(yōu)化過的所以執(zhí)行GoogleNet會特別快;當(dāng)你換到VGG Net的時候這款A(yù)SIC還是可以用的,只是執(zhí)行效率相比執(zhí)行GoogleNet時要打個折扣,不過無論如何都要比CPU快得多。
至于ASIC上市時間慢的問題,目前也是有辦法可以解決的,就是使用SoC+IP的方法。既然設(shè)計ASIC一家公司做太花時間,那能不能外包甚至眾籌呢?完全可以!許多SoC芯片就是這樣做出來的。這里首先要向大家介紹SoC的概念。SoC全稱是“片上系統(tǒng)(System-on-chip)”,亦即集成了許多不同模塊的芯片。就拿多媒體應(yīng)用的芯片舉例,早些年每一個多媒體應(yīng)用的模塊(音頻編解碼,MPEG播放編解碼,3D加速等等)自己都是一塊ASIC。后來電子業(yè)界發(fā)現(xiàn)每個模塊都做ASIC成本太高,而且最后電子產(chǎn)品的體積也很難做小,不如把所有的模塊都集成到同一塊芯片上。這塊芯片集成了多個模塊,并由一個中央控制單元通過總線控制每個模塊的運作,就是SoC。例如,現(xiàn)在高通公司的Snapdragon就是一塊典型的SoC,上面集成了GPU,視頻/音頻編解碼,相機圖像信號處理單元(ISP),GPS以及有線/無線連接單元等等。SoC上面的每一個模塊都可以稱為IP,這些IP既可以是自己公司設(shè)計的(如Snapdragon上面的調(diào)制解調(diào)器就是高通自己設(shè)計的),也可以是購買其他公司的設(shè)計并整合到自己的芯片上,例如蘋果A系列處理器里用的GPU就使用了Imagination的PowerVR IP。SoC+IP提供了一種靈活而快速的模式,可以想象如果蘋果不是購買IP而是自己組建團(tuán)隊慢慢做GPU,其A系列處理器芯片上市的時間至少要被延遲一年。
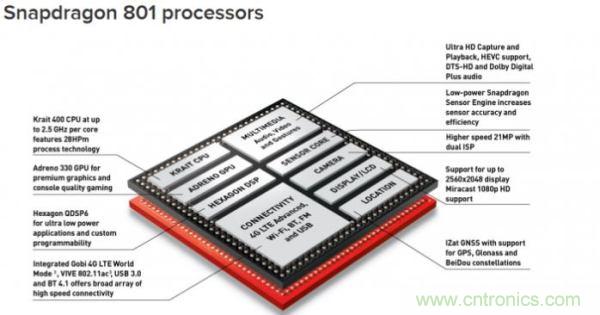
高通的Snapdragon SoC,芯片上集成了眾多IP
對于深度學(xué)習(xí)加速器而言,做成IP也是一個加速上市速度的模式。當(dāng)深度加速器成為IP時,它就不再自己做成ASIC,而是成為SoC的一部分,當(dāng)SoC需要做深度學(xué)習(xí)相關(guān)運算時就交給加速器去做。而且做成IP對于加速器來說能夠更靈活地滿足客戶的需求。例如,某加速器IP設(shè)計可以實現(xiàn)100GFlops的運算速度并消耗功耗150 mW,這時A客戶說我們需要算得快一點的加速器(150 Gflops),而且不在乎功耗(300 mW也可以)和芯片面積,那么IP公司可以根據(jù)客戶的需求快速微調(diào)自己的設(shè)計并在一兩個月內(nèi)交付(由于并不需要真正生產(chǎn)芯片,只需要交付設(shè)計)。但是如果加速器已經(jīng)做成ASIC,那要改動設(shè)計就必須重新做一塊芯片,這個過程牽扯到耗時巨大的物理設(shè)計和驗證,改動完的芯片上市時間可能是一年之后了。在SoC+IP的模式下,IP公司可以專注于加速器的前端設(shè)計并且根據(jù)客戶的需求量體裁衣,大公司則做自己擅長的后端以及芯片/封裝級驗證,可以說是大公司和小公司都可以揚長避短,各取所需,最終實現(xiàn)快速加速器設(shè)計迭代(如半年甚至一個季度一次)并跟上深度學(xué)習(xí)發(fā)展的步伐。從性能角度來說,深度學(xué)習(xí)加速器如果做成IP則和同一芯片上的CPU進(jìn)行數(shù)據(jù)通訊時可以使用高帶寬的片上互聯(lián),但是如果做成ASIC則必須走帶寬比較低功耗也比較大的芯片外互聯(lián),因此深度學(xué)習(xí)加速器作為IP成為SoC的一部分對于系統(tǒng)的整體性能也有所提升。
目前,做深度學(xué)習(xí)加速器IP的老牌公司有Ceva,Cadence等等。這些公司的設(shè)計大多是基于已有的DSP架構(gòu),設(shè)計比較保守。當(dāng)然,也有一些初創(chuàng)公司看到了深度學(xué)習(xí)加速器IP這塊市場并試圖用全新的加速器架構(gòu)設(shè)計來滿足應(yīng)用的需求,如Kneron。對于做IP的初創(chuàng)公司我個人持樂觀態(tài)度,因為首先深度學(xué)習(xí)相關(guān)加速器IP確實有市場需求,例如微軟在用于AR設(shè)備HoloLens的處理器HPU中,主要運算單元都是使用買來的加速器IP。其次,做IP并不和大的芯片公司(如NVidia, Intel)構(gòu)成競爭關(guān)系,所以壓力比較小。最后,由于做IP需要的資源較少,產(chǎn)品上市時間較快,因此維持運營對資本的壓力比較小,風(fēng)險也比直接做芯片要小,可以說是一個比較穩(wěn)妥的方案。

深度加速器IP市場既有沿用傳統(tǒng)架構(gòu)的老牌廠商(Ceva, Cadence)也有使用創(chuàng)新架構(gòu)的初創(chuàng)公司(Kneron)
結(jié)語
FPGA和ASIC在實現(xiàn)深度學(xué)習(xí)加速器方面各有所長,F(xiàn)PGA的可配置性更適合企業(yè)、軍工等應(yīng)用,而ASIC的高性能和低成本則適合消費電子領(lǐng)域(包括移動終端)。為了實現(xiàn)快速迭代,ASIC可以采用SoC+IP的模式,而這種模式也使得沒有資源量產(chǎn)芯片的中小公司可以專注于深度學(xué)習(xí)加速器IP的架構(gòu)和前端設(shè)計,并在人工智能市場上占有一席之地。
推薦閱讀:

