
【導(dǎo)讀】自大數(shù)據(jù)問世以來,用于超大規(guī)模數(shù)據(jù)中心、人工智能(AI)和網(wǎng)絡(luò)應(yīng)用的片上系統(tǒng)(SoC)設(shè)計(jì)人員正面臨著不斷演進(jìn)的挑戰(zhàn)。由于工作量的需求以及需要更快地移動(dòng)數(shù)據(jù),具有先進(jìn)功能的此類SoC變得益發(fā)復(fù)雜,且達(dá)到了最大掩模版(reticle)尺寸。本文介紹了die-to-die連接的幾種不同用例,以及在尋找用于die-to-die鏈接的高速PHY IP時(shí)要考慮的基本注意事項(xiàng)。
自大數(shù)據(jù)問世以來,用于超大規(guī)模數(shù)據(jù)中心、人工智能(AI)和網(wǎng)絡(luò)應(yīng)用的片上系統(tǒng)(SoC)設(shè)計(jì)人員正面臨著不斷演進(jìn)的挑戰(zhàn)。由于工作量的需求以及需要更快地移動(dòng)數(shù)據(jù),具有先進(jìn)功能的此類SoC變得益發(fā)復(fù)雜,且達(dá)到了最大掩模版(reticle)尺寸。因此,設(shè)計(jì)人員將SoC劃分為多芯片模塊(MCM)封裝的較小模塊。這些分離的芯片需要超短(ultra-short)和極短(extra-short)距離鏈接,以實(shí)現(xiàn)具有高數(shù)據(jù)速率的die間連接。除帶寬外,裸片到裸片(die-to-die)的連接還必須確保是極低延遲和極低功耗的可靠鏈接。本文介紹了die-to-die連接的幾種不同用例,以及在尋找用于die-to-die鏈接的高速PHY IP時(shí)要考慮的基本注意事項(xiàng)。
Die-to-die連接用例
MCM中die-to-die連接的新用例正在出現(xiàn),其中一些包括:
高性能計(jì)算和服務(wù)器SoC接近最大掩模版尺寸
以太網(wǎng)交換機(jī)和網(wǎng)絡(luò)SoC超過最大掩模版尺寸
可擴(kuò)展復(fù)雜算法的具有分布式SRAM的人工智能(AI)SoC
高性能計(jì)算和服務(wù)器SoC的面積正變得越來越大,達(dá)到550 mm2至800 mm2,從而降低了SoC的良率并增加了每個(gè)Die的成本。優(yōu)化SoC良率的更好方法是將SoC分為兩個(gè)或多個(gè)相等的同質(zhì)die(如圖1所示),并使用 die間PHY IP連接 die。在這種用例中,關(guān)鍵的要求是極低延遲和零誤碼率,因?yàn)楦〉亩鄠€(gè) die的表述和表現(xiàn)必須像單一die一樣。
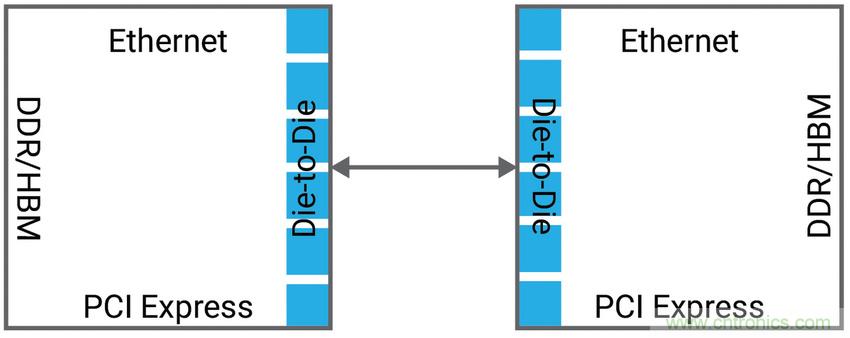
圖1:需要die-to-die連接的高性能計(jì)算和服務(wù)器SoC示例
以太網(wǎng)交換機(jī)SoC是數(shù)據(jù)中心的核心,必須以快于12Tbps到25Tbps的速率傳送數(shù)據(jù),這需要256個(gè)通道的100G SerDes接口,因此無法將這種SoC裝入800 mm2大小的掩模版。為克服這一挑戰(zhàn),設(shè)計(jì)人員將SoC拆分為這樣一種配置:其中,內(nèi)核die被I/O die包圍,如圖2所示。然后,使用Die-to-die收發(fā)器將內(nèi)核die連接到I/O die。
在這種用例中,僅當(dāng)die-to-die收發(fā)器的帶寬密度遠(yuǎn)優(yōu)于I/O die中的長(zhǎng)距離SerDes時(shí), die拆分才有效用。因此,關(guān)鍵參數(shù)是每毫米的die邊緣(die-edge)帶寬密度。
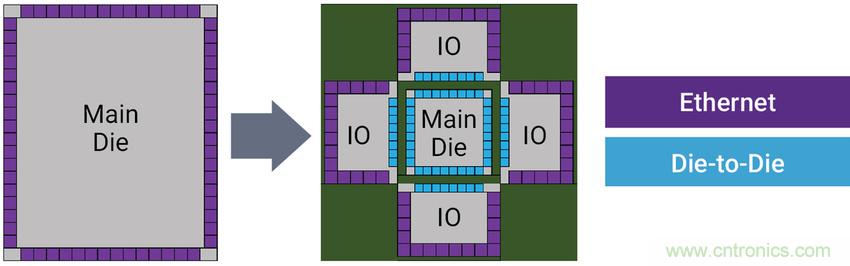
圖2:需要die-to-die連接的以太網(wǎng)交換機(jī)SoC示例
在一款A(yù)I SoC中,每個(gè)die都包含智能處理單元(IPU)和位于每個(gè)IPU附近的分布式SRAM。在這種用例下,一個(gè)die中的IPU可能需要依賴于極低延遲的短距離die-to-die鏈接來訪問另一die中SRAM內(nèi)的數(shù)據(jù)。
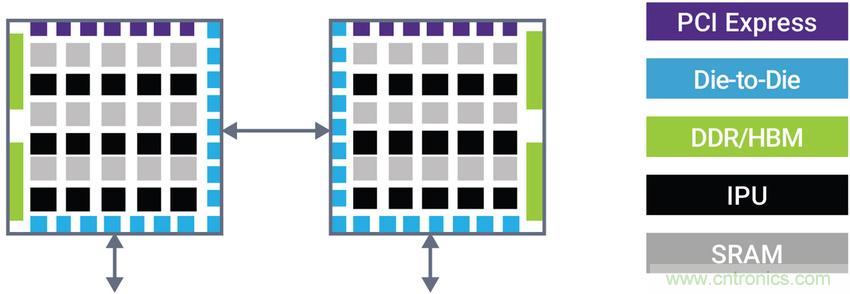
圖3:需要die-to-die連接的AI SoC示例
在所有這些用例中,用于die-to-die連接的理想高速PHY可以簡(jiǎn)化MCM封裝要求。由于每個(gè)通道的吞吐量高達(dá)112 Gbps,因此在通道數(shù)量相對(duì)有限的情況下可實(shí)現(xiàn)非常高的總吞吐量。在這種情況下,封裝走線間距和堆疊可能比較保守(L /S通常為10u /10u)。在這些用例中,也可以使用傳統(tǒng)、低成本、基于有機(jī)基材料的封裝。
Die-to-die連接的高速PHY IP要求
光互聯(lián)論壇(OIF)正在定義電氣I/O標(biāo)準(zhǔn),以在超短距離(USR)和極短距離(XSR)鏈路上以高達(dá)112Gbps的數(shù)據(jù)速率傳輸數(shù)據(jù)。這些規(guī)范定義了die-to-die的鏈接(即:封裝內(nèi))以及die-to-die到與該SoC位于同一封裝內(nèi)的光學(xué)引擎的鏈接,從而顯著降低了功耗和復(fù)雜性,并實(shí)現(xiàn)了極高的吞吐量密度。
在研究用于MCM中的die-to-die連接的高速PHY IP方案時(shí),SoC設(shè)計(jì)人員必須考慮幾個(gè)基本功能,包括:以千兆位或兆兆位每秒(Gbps或Tbps)度量的數(shù)據(jù)吞吐量或帶寬;以每比特皮焦耳(pJ/bit)為單位檢視的能源效率;以納秒(ns)為單位測(cè)量的延遲;以毫米(mm)為單位表度的最遠(yuǎn)鏈接距離;以及誤碼率(無單位)。
數(shù)據(jù)吞吐量或帶寬
為了實(shí)現(xiàn)與其它收發(fā)器的互操作性, die-to-die PHY IP必須確保符合USR和XSR鏈路的相關(guān)OIF電氣規(guī)范。支持脈沖幅度調(diào)制(PAM-4)和不歸零(NRZ)信令對(duì)于滿足兩種鏈路的要求并實(shí)現(xiàn)每通道最大112Gbps帶寬至關(guān)重要。這種信令支持非常高的帶寬效率,因?yàn)樵贛CM中的die之間傳輸?shù)臄?shù)據(jù)量非常大,因此帶寬效率是至關(guān)重要的要求。數(shù)據(jù)移動(dòng)速率通常在每秒兆兆位水平,這就限制了分配給USR和XSR鏈路的芯片邊緣(前端/ beach front)的大小。
但是,同樣重要的是支持多種數(shù)據(jù)速率。通常,期望在假設(shè)其數(shù)據(jù)速率與內(nèi)部建構(gòu)數(shù)據(jù)速率相匹適或支持chip-tp-chip協(xié)議所需的所有數(shù)據(jù)速率的條件下,實(shí)現(xiàn)die-to-die的鏈接。例如,即使在諸如32Gbps這樣的高速下,PCI Express也必須支持低至2.5Gbps的數(shù)據(jù)速率以進(jìn)行協(xié)議初始化。
鏈接距離
在die-to-die的實(shí)現(xiàn)中,大量數(shù)據(jù)必須流經(jīng)橋接die間間隙的短數(shù)據(jù)路徑。為保證將die放置在封裝基板上時(shí)的最大靈活性,PHY IP必須支持TX和RX之間50mm的最長(zhǎng)距離。
能效
能效成為重要的因素,尤其是在將SoC功能劃分為多個(gè)同質(zhì)die的用例中。在這種情況下,設(shè)計(jì)人員尋求在不影響SoC總功耗預(yù)算的情況下在die之間推送大量數(shù)據(jù)的方法。理想的die-to-die PHY IP的能效應(yīng)好于每比特1皮焦耳(1pJ/bit)或等效的1mW/Gbps。
延遲和誤碼率
為了使die之間的連接“透明”,延遲必須極其低,同時(shí)必須優(yōu)化誤碼率(BER)。由于采用了簡(jiǎn)化的架構(gòu), die-to-die PHY IP本身可實(shí)現(xiàn)超低延遲,而BER優(yōu)于10e-15。根據(jù)鏈路距離,可能需采用前向糾錯(cuò)(FEC)機(jī)制保護(hù)互連,以實(shí)現(xiàn)如此低的BER。 FEC延遲會(huì)影響方案的整體延遲。
Macro 擺放
除了這些與性能相關(guān)的參數(shù)外,PHY IP還必須支持在die所有位向的放置,以實(shí)現(xiàn)die以及MCM的高效平面規(guī)劃。宏(macro)的優(yōu)化布局可實(shí)現(xiàn)低耦合的高效die間布線、優(yōu)化的die和MCM大小、并最終提高能效。
選擇die-to-die的PHY IP時(shí),還有許多其它考慮因素,包括整合進(jìn)可測(cè)試性功能,以便能夠在封裝之前對(duì)die進(jìn)行生產(chǎn)測(cè)試,但前述幾點(diǎn)是最重要的。
結(jié)論
更高的數(shù)據(jù)速率和更復(fù)雜的功能正在增加用于超大規(guī)模數(shù)據(jù)中心、AI和網(wǎng)絡(luò)應(yīng)用的SoC的大小。隨著SoC尺寸接近掩模版尺寸,設(shè)計(jì)人員被迫將SoC分成較小的die,這些die封裝在多芯片模塊(MCM)中,以實(shí)現(xiàn)高良率并降低總體成本。然后,MCM中的較小die通過die-to-die互連進(jìn)行鏈接,這些互連具有極低功耗和 而且每個(gè)die邊緣都具有高帶寬。在高性能計(jì)算和AI應(yīng)用中,大的SoC被分為兩或多個(gè)同質(zhì)die;在網(wǎng)絡(luò)應(yīng)用中,I/O和互連內(nèi)核被分為單獨(dú)的die。這種SoC中, die-to-die的互連必須不影響整體系統(tǒng)性能,并且要求低延遲、低功耗和高吞吐量。這些要求推動(dòng)了對(duì)諸如Synopsys的DesignWare®USR/XSR PHY IP這樣的高吞吐量die-to-die PHY的需求,該IP支持MCM設(shè)計(jì)中的die-to-die鏈接,每通道的數(shù)據(jù)速率高達(dá)112Gbps,且能效極高。DesignWare USR/XSR PHY IP符合用于USR和XSR鏈接的OIF CEI-112G和CEI-56G標(biāo)準(zhǔn)。
免責(zé)聲明:本文為轉(zhuǎn)載文章,轉(zhuǎn)載此文目的在于傳遞更多信息,版權(quán)歸原作者所有。本文所用視頻、圖片、文字如涉及作品版權(quán)問題,請(qǐng)聯(lián)系小編進(jìn)行處理。
